

Neues von DEVONtechnologies
Überprüfen Sie die Texterkennung
Texterkennung (OCR) ist eine Technologie in z.B. DEVONthink Pro, die die Pixel in einem Bild oder PDF betrachtet und versucht herauszufinden, welche Buchstaben und Zahlen sie repräsentieren. Diese Zeichen legt sie dann in eine Textebene unterhalb des Originalbildes, so dass das Dokument unverändert erscheint, aber nun maschinell durchsuchbar ist. (Hinweis: Die Texterkennung kann auch Textdokumente aus den erkannten Daten erstellen.)
Allerdings könnte es sein, dass Sie manchmal Dokumente nicht finden, obwohl ihr Text von der OCR erkannt sein sollte. Eventuell haben Sie ein älteres Dokument von jemandem erhalten, dessen Texterkennung weniger genau arbeitete. Oder die Qualität des ursprünglichen Bildes war schlecht, was es der Texterkennung schwer macht, die Zeichen zu entziffern.
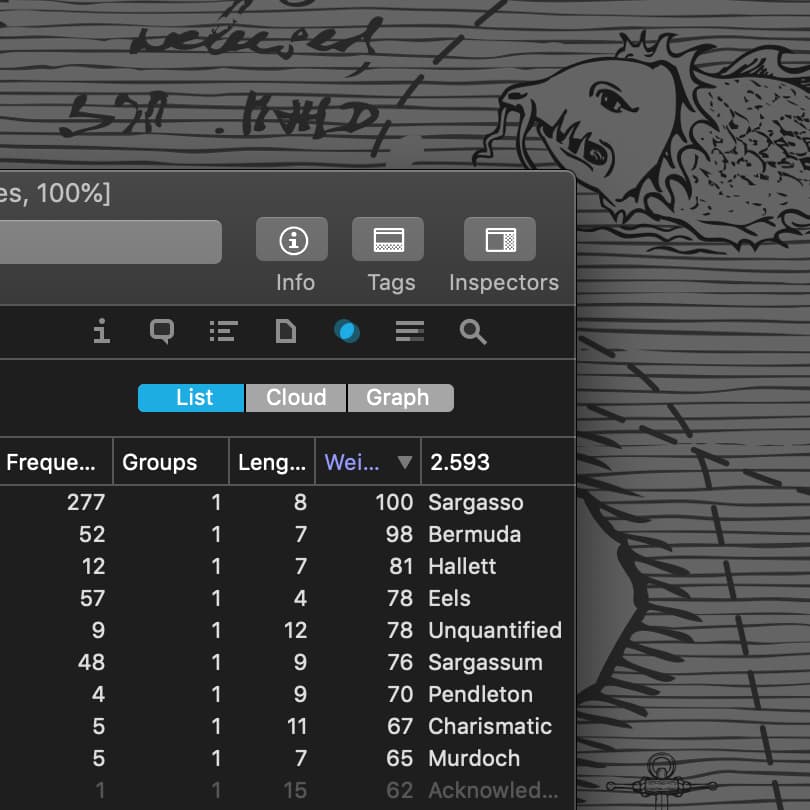
Sie können die Genauigkeit der Texterkennung überprüfen, indem Sie das PDF auswählen, die Inspektoren öffnen, und auf die Konkordanz wechseln. Falls die Textebene schlechten Text enthält, werden Sie aneinandergekettete oder sogar unsinnige Wörter sehen.
Für eine noch bessere Analyse können Sie das PDF mithilfe von Daten > Konvertieren > in reinen Text umwandeln und den gesamten Text begutachten.
Hinweis: Dieser Artikel bezieht sich auf eine ältere Programmgeneration. Bedienelemente, Menüpfade und Verfahren können abweichen.